


Notes #01: Data Formats & Encoding
Everything You Need to Know About Data Formats and Encoding Schemes for OLAP.

This article consolidates everything I've learned about Data Formats & Encoding for OLAP. It’s a bit unstructured, but I hope you will get something out of it!
Format Design Decisions
All "modern" storage models (like Parquet and ORC) make certain design decisions.

Storage Models in DBMS
A DBMS’s storage model specifies how it physically organizes tuples on disk and in memory. There are three prominent storage models.

Model (NSM)
also known as the row-oriented storage model, stores data row by row.
all the attributes (columns) of a tuple (row) are stored together contiguously on disk.
page sizes are typically some constant multiple of 4 KB hardware pages.
Oracle (4 KB), Postgres (8 KB), MySQL (16 KB)
Use Cases: Best suited for transactional systems (OLTP) where operations often involve reading or writing entire rows.
Advantages:
Efficient for queries that need to access multiple columns of a single row.
Fast insertion, update, and deletion operations.
Disadvantages:
Less efficient for analytical queries (OLAP) that process large volumes of a few columns.
Scans over large datasets can be slower due to the need to read entire rows.

Decomposition Storage Model (DSM)
Stores each attribute (column) for all tuples (row) contiguously in a block of data.
Maintain a separate file per attribute (column) with a dedicated header area for meta-data about entire column.
Requires conversion of variable-length data to fixed-length using techniques like dictionary compression for efficient tuple access.
Use Case: Ideal for OLAP workloads, which involve large, read-only scans over subsets of a table's attributes (columns).

Hybrid Storage Model (PAX)
Combines aspects of both NSM and DSM by vertically partitioning attributes within a database page and horizontally partitioning data into row groups.
Horizontally partition data into row groups
Each row group contains its own meta-data header about its contents
Then vertically partition their attributes into column chunks
Global meta-data directory contains offsets to the file's row groups
typically stored at the bottom of the file, if the file is immutable (Parquet, Orc)
Use Case: Suitable for systems requiring benefits of both row and column stores, such as
ParquetandORCfile formats.

Interoperability
“Most DBMSs use a proprietary on-disk binary file format for persistent data. The only way to share data between systems is to convert data into a common text-based format: CSV, JSON, XML.”
You can't share data across different DBMS system, you can't take postgres data directory files and give it to mysql to read it:
only way to is to dump it into
CSV,JSON, etc., and ingest it in the other systemNote:
DuckDBis able to read files from different systems
Same applies for Snowflake, data interoperability can be achieved by exporting data into text-based formats like CSV, JSON, or using data exchange formats such as Parquet and ORC.
Open-Source Persistent Data Formats
HDF5 (1998): Multi-dimensional arrays for scientific workloads.
Apache Avro (2009): Row-oriented format for Hadoop that replaced SequenceFiles.
Apache Parquet (2013): Compressed columnar storage from Cloudera/Twitter for Impala.
Apache ORC (2013): Compressed columnar storage from Meta for Apache Hive.
Apache CarbonData (2016) Compressed columnar storage with indexes from Huawei.
Apache Arrow (2016): In-memory compressed columnar storage from Pandas/Dremio.
Apache Parquet and Apache Arrow
File Meta-Data
Files are self-contained to increase portability
They contain all the necessary information to interpret their contents without external data dependencies.
Table Schema
Row Group Offsets / Length
Tuple Counts / Zone Maps
Parquet uses Apache Thrift for defining and serializing the metadata structures.
Note: in systems like
Postgresthese meta-data is stored in thesystem catalog- the actual data is stored in separate data files managed by the database system.
Format Layout
The most common formats today use the
PAXstorage modelThe size of row groups varies per implementation and makes compute/memory trade-offs:
Type System
Type systems define how data types are represented, stored, and processed in database systems and data formats.
Physical Types: low-level byte representation, determining how data is actually stored and accessed on disk or in memory.
IEEE-754: A standard for floating-point arithmetic used to represent real numbers in binary.
Logical Types: higher-level abstraction that maps to physical types.
DATE, TIME, TIMESTAMP: Logical types for date and time values. They are stored as integers but include metadata to interpret them as date and time values.
Example: Parquet Types
Encoding Schemes
Dictionary Encoding
Replace frequent values with smaller fixed-length codes, maintaining a mapping from codes to original values.
Codes can be positions (using a hash table) or byte offsets in the dictionary.
Optionally sort dictionary values.
Further compress the dictionary and encoded columns.
Parquet: RLE + BitpackingORC: RLE, Delta Encoding, Bitpacking, FOR

Block Compression
Historical Context: Previously essential due to slow networks and disks, making data retrieval and transfer costly.
The performance benefits depends on the specific context, including the storage system, the network environment, and the data characteristics.
Storage System Speed:
Compression helps more on slow storage systems.
On fast systems SSDs, decompression time can outweigh benefits.
Network Connection Speed:
Uncompressed data transfer is best when the server and client are on the same machine.
Light compression for high-speed connections.
Heavy compression for slow connections (e.g., 10Mbit/s).
Data Distribution:
Compression effectiveness depends on data distribution.
Number of Columns:
Column-specific algorithms may be less effective with many columns.
Value Range:
Wide value ranges can reduce the performance of specialized compression algorithms.
Data Type:
Integer values with small ranges or repetitive patterns compress well.
Textual data with variations compresses less effectively.
Presence of NULL Values:
Efficient handling of NULL values improves compression.
General-purpose algorithms like:
Drawback vs Benefit: For instance,
Zstdcan make files smaller, which speeds up data scans when using slow storage devices where the I/O time is the bottleneck. However, this benefit diminishes with faster storage devices (SSD) because the time saved on I/O becomes less significant compared to the time needed to decompress it.
Filters
Are auxiliary embedded data structures to speed up query processing. They help to prune data during table scans, reducing the amount of data that needs to be read and processed.
Zone Maps: Maintains
min/maxvalues per column at file and row group levelsWhen a query includes a range predicate (e.g., WHERE age BETWEEN 25 AND 35), the query engine can consult the Zone maps to quickly determine if the zone potentially contains matching values.
Bloom Filters: Probabilistic data structures used for tracking the existence of values for each column in a row group. They can quickly determine if a value might be present in a data block, but they cannot definitively confirm its absence.
When a query includes a point predicate (e.g., WHERE city = 'London'), the engine checks the Bloom filter associated with the 'city' column. If the filter suggests that 'London' might exist in the block, the block is read and checked.
It can yield false positives, indicating a value exists when it does not),
However, they will never produce false negatives. Meaning if the filter indicates a value is not present, it is guaranteed to be absent from the data block.
Nested Data
To represent semi-structured objects (e.g., JSON, Protobufs), columnar storage formats encode the contents of these objects as if they were regular columns using different strategies.
Parquetadopts the Dremel modelORCutilizes a length and presence based model
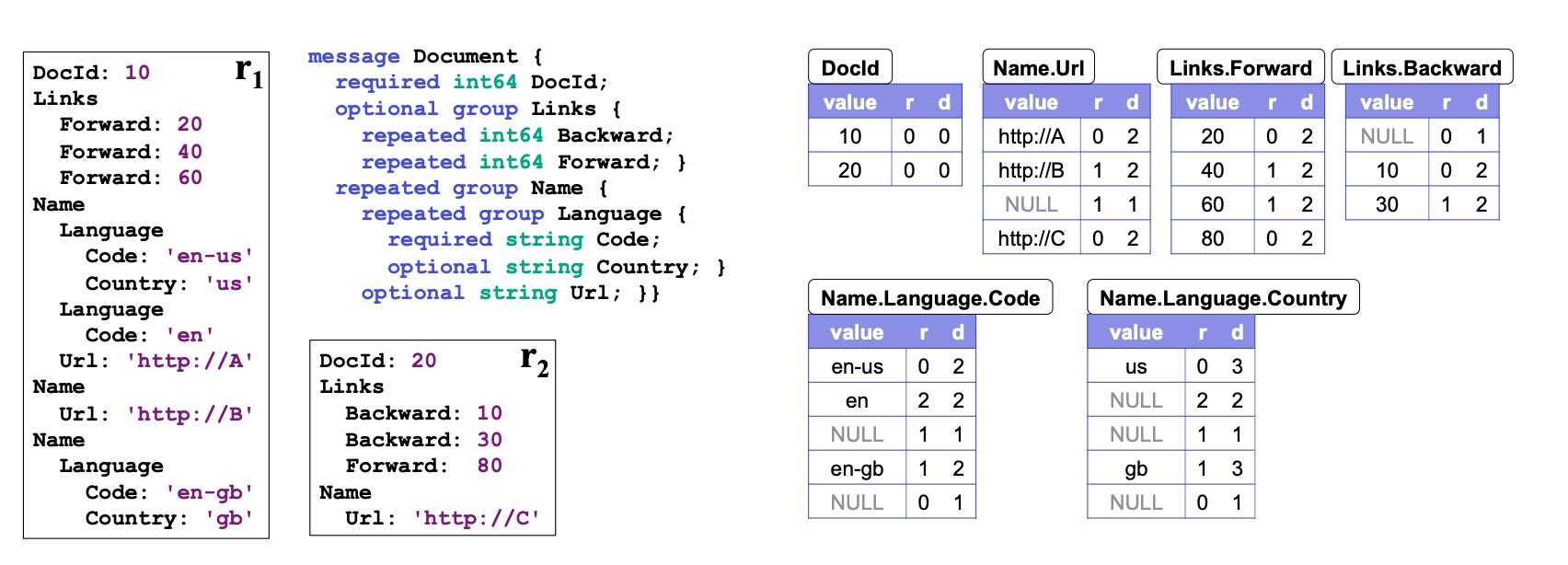
Dremel introduced the concept of repetition and definition levels
Repetition Level (R): How deep we are within repeated fields. This tells us how many times we're "inside" a repeated structure.
Definition Level (D): How many fields in a path are actually present (not null). This helps us understand which parts of a nested structure are filled in.
think of the definition level as a type of counter that increments based on how many fields in a nested structure are actually defined (i.e., present and not null). When a field is missing (null), the counter stops incrementing, indicating where the data structure starts to have undefined (null) values.

Repetition Level
DocId: 10 (R=0): The document's ID is at the root level.
Name (R=0): The first
Namegroup is directly under the root.Language (R=1): The first
Languagegroup withinNameis at R=1.Code: 'en-us' (R=2): Inside the
Languagegroup, thisCodefield is at repetition level 2.
- Root (Level 0)
- Folder A (Level 1)
- Folder B (Level 2)
- File 1
- Folder A (another instance) (Level 1)
- Folder C (Level 2)
- File 2Definition Level
Path to
Name.Language.Code (en-us):Document -> Name -> Language -> CodeDefinition Level 4 because
CodeandCountryare present.
Path to
Name.Language.Code (en):Document -> Name -> Language —> Codethe maximum definition level for this path would be 4 if all fields (including
Country) were present. In this case,Countryis missing (null), so the definition level is 3 instead of 4.
Advanced Compression Schemes
Due to the repetitiveness of data in the real world, dictionary encoding is a viable option for all data types and not just strings.
Lightweight encoding schemes can be decoded much faster due to a decrease in branch mis-predictions at runtime.
Block compression is becoming unnecessary as network and disk are becoming faster and CPU is becoming the bottleneck.
Parquet/ORC Deficiencies:
No Statistics: Lacks histograms, sketches, and other statistical data.
No Incremental Schema Deserialization: Cannot deserialize schemas incrementally.
In these formats, the entire schema of the dataset must be read and deserialized all at once. This can be inefficient and resource-intensive, especially for schemas with a large number of columns or complex nested structures.
BtrBlocks
BtrBlocks: Efficient Columnar Compression for Data Lakes
Encoding Strategies: It employs aggressive nested encoding schemes surpassing
ParquetandORC, including new methods for floating-point values.Run-length encoding (RLE) & One Value: Stores runs like (42, 3) instead of repeating values {42, 42, 42}. It's ideal for blocks with only one unique value.
Frequency encoding: Handles skewed distributions by using variable code lengths based on data frequency. It stores the top value efficiently and uses a bitmap for exceptions.
For example, if a certain value appears in 70% of the records, it might be assigned a very short binary code, like
1.
Frame of Reference (FOR) + Bit-packing: Encodes integers as deltas to a base value (e.g., base 100 for {5, 1, 13} instead of {105, 101, 113}). Combined with bit-packing, it reduces unnecessary leading bits.
Dictionary Encoding
Fast static symbol table (FSST)
Pseudodecimals
The benchmarks in the paper show scans on real-world data are 2.2× faster and 1.8× cheaper when using
BtrBlocksoverParquet.
FSST: Fast Random Access String Compression
Dictionary encoding replaces repeated strings with fixed-size integer codes, which works well when many strings are identical.
It struggles with similar but not identical strings since it requires exact matches for compression.
Random Access: Requires decompressing the whole dictionary to access one string.
FSST (Fast Static Symbol Table) takes a different approach by identifying common substrings (1 to 8 bytes long) and replacing them with 1-byte codes.
Random access: allows to decompress individual strings without needing to decompress the entire block, making it more efficient for operations like lookups and joins.
Compression of similar strings: FSST excels at compressing similar but not identical strings, like URLs or email addresses, by focusing on common substrings, while dictionary encoding relies on exact matches.
Efficiency with short strings: FSST is optimized for compressing short strings, which are common in database systems, unlike general-purpose compressors like LZ4, often used with dictionary encoding.

Fastlanes
SIMD across different CPUs: Modern CPUs come with various SIMD (Single Instruction, Multiple Data) instruction sets, which can make coding complex and cumbersome. FastLanes simplifies this challenge by introducing a virtual 1024-bit SIMD register and instruction set. This virtual set is designed to work seamlessly across all major CPU brands—Intel, AMD, and ARM.
By standardizing SIMD operations, FastLanes makes it easier to write and maintain code, ensuring that it performs optimally across various hardware platforms without the usual complexity of maintaining platform-specific SIMD code.
/*
with FastLanes, you write the `processImage` function once and it works across all platforms, with the FastLanes tool automatically handling the conversion to the correct SIMD instructions for Intel, AMD, and ARM.
This greatly reduces the complexity and maintenance overhead, allowing users to focus on the algorithm rather than the specifics of each CPU architecture.
*/
// Intel-specific SIMD code (AVX)
__m256i processImage_AVX(__m256i data) {
// AVX-specific processing
}
// ARM-specific SIMD code (NEON)
uint8x16_t processImage_NEON(uint8x16_t data) {
// NEON-specific processing
}
// Unified SIMD code using FastLanes
FastLanes_SIMD processImage(FastLanes_SIMD data) {
// Processing using virtual SIMD register
}Scalar code, SIMD speed: Allows for a scalar (non-SIMD) code path that achieves near-SIMD performance. Modern compilers can then auto-vectorize this code, making it both portable and high-performance.
/*
During compilation, the compiler may transform this scalar loop into SIMD instructions that operate on multiple elements of the arrays simultaneously.
*/
// Scalar code without explicitly using SIMD instructions.
void sumArrays(float* a, float* b, float* result, int length) {
for (int i = 0; i < length; i++) {
result[i] = a[i] + b[i];
}
}Decoding dependencies: Light-weight compression schemes, like delta encoding, is sequential as it computes differences between neighboring values, this limits SIMD parallelism.
FastLanes introduces the "Unified Transposed Layout" a data reordering scheme that restructures data (tuples) to break these dependencies, enabling SIMD operations.
Nested Data-Type Encodings in Fast Lanes
Implementation of new compression schemes in FastLanes, showing a significant improvement in compression ratios compared to other systems (Parquet).
Bit-sliced encoding
In traditional DBMS, when querying for specific values, like a
zipcode, the entire value of each zip code must be checked.using a technique called bit-slicing can optimize this process significantly
BitWeaving improves upon the bit-sliced index with a new storage layout that is optimized for memory access and early pruning.
Data Formats Challenges
Variable-Length Runs: Formats like
Parquet,ORC, andBtrBlocksstore data in variable-length runs, which complicates decoding during query processing. Handling these varying lengths adds computational overhead, affecting both scalar and vectorized operations.Delta Encoding Overhead:
ParquetandORCuse Delta encoding, which compresses data by storing differences between values. While efficient for compression, this method creates dependencies between values, leading to decoding challenges.SIMD Limitations: SIMD, which processes data in parallel, struggles with Delta-encoded data due to dependencies between consecutive values. These dependencies hinder SIMD's effectiveness.
Sequential Metadata Parsing: Parquet stores schema and column metadata in a footer, serialized with Thrift. Reading any column requires parsing the entire metadata, which is inefficient for large datasets, especially when only a few columns are needed.
Lack of Random Access: Parquet's metadata layout doesn’t allow efficient random access to specific columns. This results in higher latency when selecting columns from wide tables, as the system must process metadata for all columns, not just the ones needed.
Wide-Table Projections: ML models often rely on thousands of features stored as columns. However, formats like
ParquetandORCstruggle with efficiently reading subsets of these columns due to heavy metadata and poor random access.Vector Embeddings: ML datasets frequently include vector embeddings, but current formats are not optimized for storing and accessing these high-dimensional arrays, leading to poor compression and scanning inefficiencies.
Low-Selectivity Queries: ML workloads often require retrieving small, specific subsets of data. Existing formats lack efficient indexing and filtering mechanisms, particularly in large cloud-stored datasets.
Unstructured Data Storage: ML datasets may also contain unstructured data like images and audio. Current formats are not well-equipped to efficiently manage and access large binary objects alongside structured data.